 UNICODE:
UNICODE:
Décrire ce qui n’existe pas …
A l’invite de Patrick Andries

sur fr.comp.normes.unicode,
Compilateur répondait début août 2002 :
>
J'aimerais obtenir,
afin qu'on y réponde dans un article à publier,
les questions que se posent les utilisateurs
au sujet d'Unicode
ou les critiques qu'ils émettent
à l'encontre de ce standard.
>
Confronté à une difficulté pratique,
je viens de lire votre demande,
et y réponds un peu tardivement.
Ma question est relativement simple:
peut-on créer par Unicode des caractères chinois
qui n'y figurent pas
- pas encore s'ils sont rares,
- ou non susceptibles d'être codifiés
car ils n'existent pas encore ?
A la main,
ceci ne présente aucune difficulté et peut rendre service –
j'avais ainsi à inscrire dans un de ces hôtels de province
un collègue dont le nom se prononçait plus ou moins Sichons
- et cette partie de la fiche devait être obligatoirement remplie
en caractères respectant suffisamment la phonétique
pour que l'hôte se retourne quand on l'appellerait.
J'ai alors inventé un 人+十, 人+三
qui a donné toute satisfaction
(il s'agissait à l'évidence d'une personne,
dont le nom était, plus ou moins, Sichons).
L'on pouvait certes trouver mieux - mais
au moins cette approximation m'était possible,
et n'a choqué personne.
Quel truc utiliser en informatique pour arriver au même résultat ?
Est-il possible, en somme, de combiner
亻 avec 5341, puis avec 4E09 ?
Je ne crois pas, mais sait-on jamais ...
Le mieux auquel je sois parvenu, par FF72
(http://www.unicode.org/charts/PDF/UFF00.pdf .
Voyez si l'on cherche ! ),
イ十 イ三 au lieu de 亻十 亻三 ne me satisfait guère.
Et puis cela ne marche qu'avec les katakana disponibles ...
Ø Jores -
Ce que je me rappelle d'avoir lu il y a peu de semaines
quand, à propos des radicaux 'oreille droite'/'oreille gauche',
je faisais une recherche sur Internet à ce sujet
c'est que le projet Unicode prévoit la possibilité
de créer de nouveaux caractères à partir de clé
et d'autres signes,
mais que personne ne l'a encore fait,
même pas des entreprises.
Mon interprétation
c' est qu'en ce moment ce n'est pas possible de le faire.
>
JVG : C'est bien ce que je pressentais
- avec, malgré tout, une (toute petite) ouverture:
puisque le projet "prévoit la possibilité de",
que faut-il pour mettre en pratique ?
Jean-Marc Desperrier
> Le chapitre 11 de la traduction française d'unicode
http://iquebec.ifrance.com/hapax/pdf/Chapitre-11.pdf
explique dans le chapitre "Description idéophonographique"
comment de nouveaux caractères peuvent être décrits
grâce aux éléments présents dans le bloc suivant :
Ø (http://www.unicode.org/charts/PDF/U2FF0.pdf )
Ø Cependant en plus de ne pas être implémenté en pratique,
une telle solution ne permet pas justement de décrire
très précisément
la forme que doivent prendre les traits,
ça marche pour les cas simple du type
coller le caractère personne
et celui pour trois,
mais pas pour des choses plus complexes.
>
JVG : Merci pour toutes ces précisions.
J'étais au départ moins pessimiste que vous
sur les possibilités offertes par les éléments d'information
sur la composition de nouveaux caractères (bloc 2FF0).
Cette méthode est en effet voisine de deux autres
utilisées pour la représentation de caractères ou de kanjis
(Cangjie * ou SKIP)
qui semblent donner toute satisfaction à leurs utilisateurs.
L'ennui, c'est qu'il y a différentes possibilités
pour décrire le caractère souhaité,
même s'il est relativement simple,
et que les règles établies pour les décrire
afin d'arriver à une relation univoque sont donc très strictes,
parfois limite arbitraire.
Chacune des deux méthodes a en outre
son reliquat d'inclassables,
ce qui témoigne de certaines faiblesses systématiques
- normal, puisqu'elle utilisent une logique différente
de celle de la construction des caractères,
fondée sur les 21 traits de base.
Toutes les méthodes de classification chinoises
se sont heurtées à ces difficultés,
y compris les dictionnaires de facture classique
(certains caractères figurent sous plusieurs clefs,
et une poignée d'irréductibles sous aucune).
Ceci étant, la complexité du caractère
n'est pas un obstacle dirimant à sa description.
Exemple 瀿, 20 traits:
clef de l'eau 氵 à gauche,
partie droite décomposée en supérieure et inférieure,
partie supérieure deux parties horizontale, 每 et 夂,
partie inférieure 糸 ou
décomposée à son tour en deux parties verticales,
幺 et 小,
un beau bébé analysable en
U+2FF0氵
2FF1
2FF0
2FF1
qui devrait faire l'affaire:
la description de la partie traitée d'un caractère
est toujours suivie du contenu de cette partie.
Ici, deux parties verticales (2FF0),
la partie de gauche simple,
celle de droite décomposée en haut et bas (2FF1),
le haut décomposé en deux verticales (2FF0)
et le bas en deux horizontales (2FF1).
Le résultat cependant 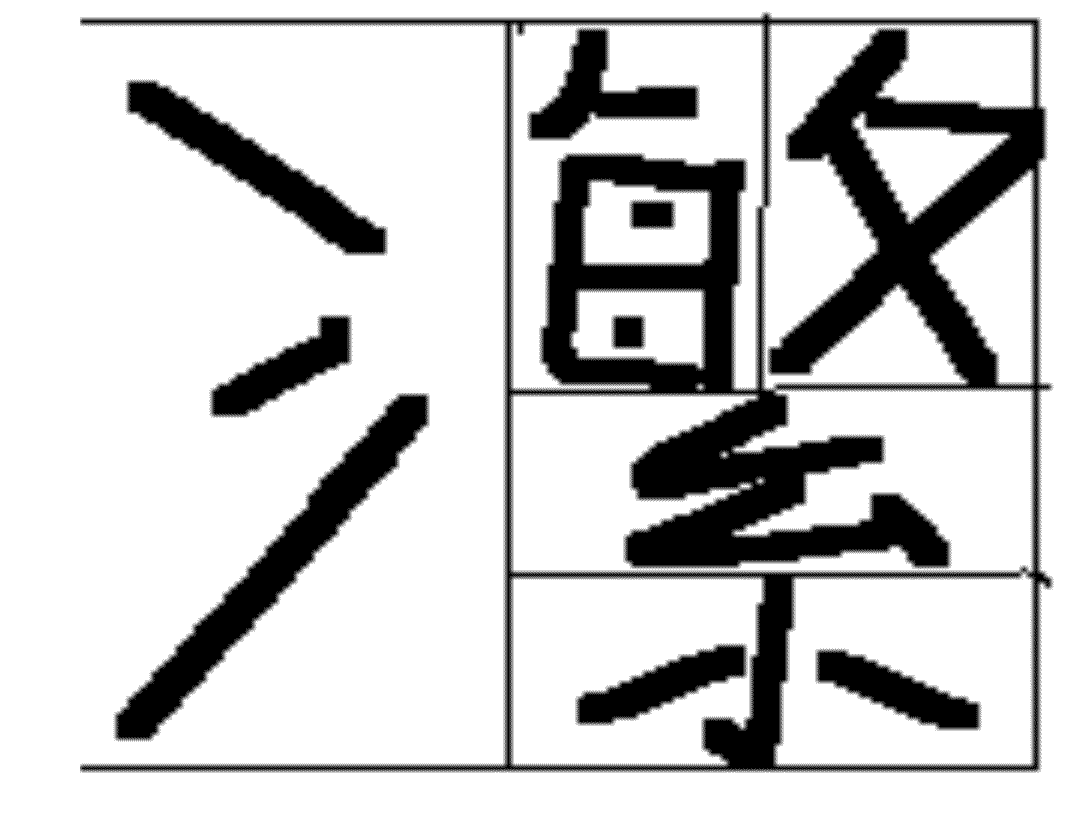
( vous pardonnerez la naïveté du trait.
Je suis très mauvais graphiste, alors, à la souris ...)
est décevant:
aucune information n'a pu être fournie
sur la taille respective des composantes,
d'où une partie gauche surdimensionnée.
Cette discrétion des clefs en composition
pourrait certes être prise en compte par le biais
de nouveaux symboles,
mais le registre consacré à l'opération
n'y suffirait probablement pas
- il ne reste que 3 "disponibles" dans la série 2FF.
Ceci pourrait être corrigé
par un logiciel d'interprétation des codes,
puisqu'au demeurant les codes concernés
(ceux dont les caractères prennent
un aspect filiforme ou tassé)
sont relativement aisés à circonscrire,
mais nous en sommes loin.
Ø JM Desperrier :
Ø Avec les 42,711 caractères ajoutées dans unicode 3.1,
il est peut probable de trouver un caractère existant
qui n'est réellement pas encodé dans unicode.
>
Ø En fait unicode a pour but d'encoder un caractère
en fonction de son sens,
et pas en fonction des diverses formes graphiques
qu'il peut prendre (la glyphe).
La représentation à ce niveau là dépend
de la police choisie.
Donc dans la plupart des cas un caractère
qu'on ne trouve pas
existe en fait déjà dans unicode,
mais il est représenté sous une forme standardisée,
et pas exactement sous la variante souhaitée,
la solution officielle unicode est alors de trouver la police
qui le représente de la manière souhaitée
et de la sélectionner pour l'affichage.
>
JVG : On ne le répètera jamais assez
- les variantes ne sont que ce qu'elles sont,
et il y a suffisamment de raisons de confondre
des caractères distincts,
pour ne pas s'épuiser à distinguer des caractères
qui sont les mêmes ...
Mais le message a souvent du mal à passer,
surtout auprès de ceux et celles
n'ayant pas l'habitude de ces malices caractérielles
cependant fort bien acceptées par chez nous –
voir la multiplication de polices alphabétiques
toutes plus originales les unes que les autres.
A propos, polices.htm
RETOUR vers l’ ENCODEUR
VISITER CCDICT
 jvg, 26.8.2002
jvg, 26.8.2002
Attention – La page http://www.cjmember.com/
a récemment changé de
structure.
Les liens fournis sur fllcjvg
ne fonctionnent donc plus
nécessairement
mais les informations sont toujours
disponibles sur le site d’origine,
et accessibles moyennant un minimum de
recherches.
Les composantes du
bloc 2FF en format image
2FF02FF12FF2 2FF3
2FF3
2FF4 2FF5
2FF5 2FF6
2FF6 2FF7
2FF7
2FF82FF9![]() 2FFA
2FFA 2FFB
2FFB